


Building a sports prediction model is three problems stacked on top of each other. Build something predictive. Figure out how to bet on it profitably. Prove the result isn't luck.
Each layer is hard. Each is where most attempts quietly fall apart. Did you pick the right algorithm? Did you tune the right parameters? Did your backtest fool you? Is the edge real or are you just on a hot streak? On your own, these don't get honest answers — you don't know what you don't know.
Moddy is built around answering them. Thousands of model configurations from a single idea, hundreds of strategy permutations on top, a backtest that separates edge from variance, and live performance anyone can verify. Here's what's happening under the hood.
Moddy builds your idea thousands of ways
When you set up a model on Moddy, you're describing an idea: a hypothesis about how games play out, expressed through the stats and signals you think matter. What happens next is not what you'd do on your own.
On your own, your data is what it is. On Moddy, your inputs run through three analyses in parallel before training even starts: feature importance ranking (which stats actually drive predictions), correlation analysis (which signals overlap more than they should), and variance inflation analysis (subtle multicollinearity that simple correlation misses). All of this against 126 million data points spanning the last decade of MLB, NFL, and NBA — far enough back to capture real patterns, recent enough that the game still looks like the game being played today.
Real example: a creator combines batter zone contact rate with opposing starter's swinging strike rate as an interaction term — and also keeps that same swinging strike rate as a standalone input. The two come out 95.57% correlated. Different names, same signal, counted twice. Moddy catches it and pauses the test before training starts.
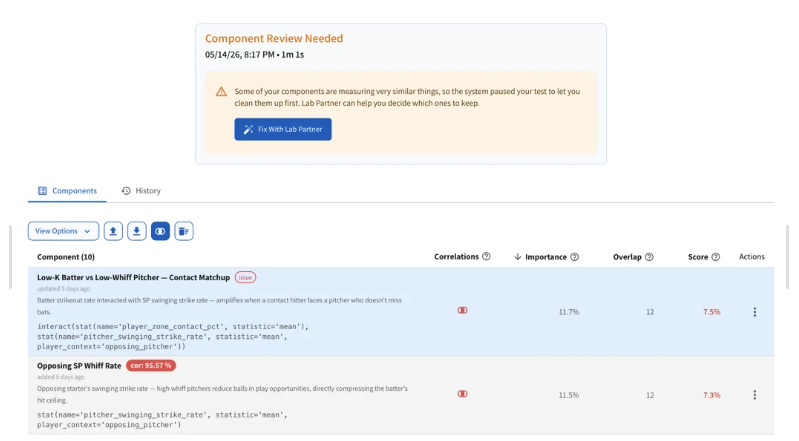
On your own, you'd pick an algorithm. Maybe two if you're ambitious. Moddy tests up to 18 different algorithmic approaches for yes/no outcomes like moneylines and spreads, and up to 15 for numeric outcomes like totals and player stats. Each one represents a different way of interpreting your idea — some simple, some highly tuned, some combining multiple approaches. Every one of them gets tested with time-series cross-validation, which respects the chronological order of games. A model training on 2022 doesn't get to peek at 2023. That's not a small thing: random shuffling, which is what most off-the-shelf tools do by default, creates an illusion of accuracy that evaporates the moment you go live.
On your own, you'd hand-tune a few parameters. Moddy runs Bayesian optimization across thousands of unique parameter combinations for each surviving algorithm — how aggressively the model learns, how complex it's allowed to get, how much it prioritizes stability over flexibility. This isn't trial and error. Bayesian optimization learns from each combination it tests, narrowing in on what matters and skipping what doesn't. It's how you search thousands of combinations without taking thousands of years.
The weaker versions drop out. The stronger ones move on. What survives isn't "the model you built." It's the strongest possible version of your idea, given the data Moddy could reach.
Moddy tests hundreds of ways to act on your prediction
A model that correctly picks the winner isn't useful on its own. At -300 odds, you'd risk $300 to win $100 — even a confident pick on the right side might not be a bet worth taking. The model's output is an input. The strategy is the product.
Most platforms stop at the prediction. Moddy treats the strategy on top of the prediction as half the work, and tests it with the same rigor as the model underneath.
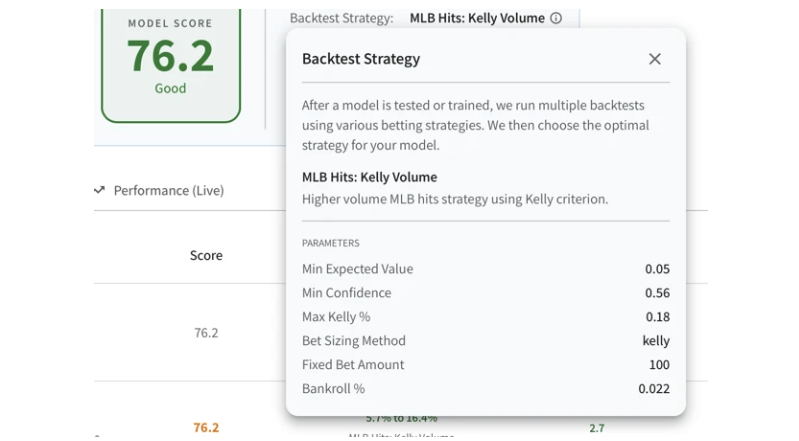
On your own, you'd bet a fixed amount when something feels like an edge. Moddy tests four distinct strategy types at dozens of threshold levels, each crossed with four bet sizing methods:
- Expected value — bet only when the math says there's a clear edge over the bookmaker's implied probability
- Confidence threshold — require both high model confidence and positive expected value before pulling the trigger; fewer bets, higher conviction on each
- Kelly Criterion — size and gate bets by edge and odds, finding the sweet spot between betting too much (one bad streak wipes you out) and betting too little (leaving money on the table)
- Outcome-specific — moneylines play differently than props or totals, so each market type gets a strategy variant that respects its dynamics
Sizing comes in fixed-amount, proportional-to-bankroll, Kelly-optimal, and confidence-weighted forms. Cross strategies, thresholds, and sizing — and you get hundreds of strategy permutations tested per model, each run against real historical games at the odds that were actually available at the time.
On your own, a regression prediction is just a number. Your model says a game will land at 52.3 points; the line is 47.5. How confident should you actually be that the over hits? That's not a question your point prediction can answer. Moddy's probability engine converts predicted values into bet probabilities using statistical distributions calibrated per sport and market type, accounting for the natural variance in outcomes. A prediction of 52.3 against a 47.5 line translates into a strong over probability. A prediction of 48.2 against that same line? Much less certain. That conversion happens before any strategy logic runs — without it, a regression model can't tell you whether to bet at all.
What you end up with isn't a prediction. It's a model, a strategy, and a way to size every bet — chosen together, because that's the only combination that actually defines an edge.
Moddy proves the edge is real
But an edge is only an edge if it survives contact with reality. A model is only as good as its honest backtest, and an honest backtest is harder than it sounds. Most platforms cut corners in ways that make their results look better than reality. Moddy doesn't.
On your own — or on most platforms — backtest code diverges from live code. Backtests run in batch with full data; live predictions run with real-time data, often through simpler code paths that "approximate" the backtest logic. The result: a model's historical performance doesn't predict its live performance. At Moddy, the exact same code that evaluates a strategy in backtest is the code that evaluates it live. No shortcuts. No "good enough" approximations. If a backtest says a model has a certain ROI over the last few seasons, the live system applies exactly the same logic, the same thresholds, the same sizing calculations.
On your own, you'd judge a model by its raw ROI or win rate. Moddy uses a composite score weighted on both prediction accuracy and profitability, then normalizes that score against every other model built for the same outcome type. If you're building an NFL moneyline model, your score reflects how it stacks up against every other NFL moneyline model on the platform — not graded in isolation, graded against the field.
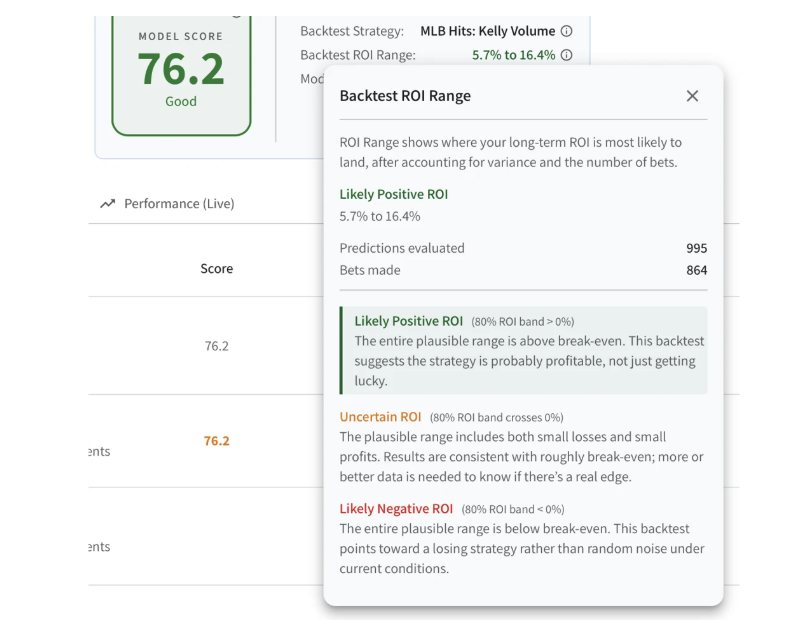
On your own, a backtest tells you "I made X%." Moddy tells you whether the X% is real edge or random variance. After accounting for the number of bets and the natural variance in outcomes, the system reports an 80% confidence band on long-run ROI. Likely Positive ROI means the entire plausible range is above break-even — the strategy is probably profitable, not just lucky. Uncertain ROI means the data could still support either side. Likely Negative ROI means the math says it's losing, not unlucky. Same statistical rigor a quant team would demand, applied to every model.
And every model's live performance is public. ROI, edge, win/loss record, and performance ratio — overall and by bet strength, sliced across last 30/60/90 days, rolling 100 and 500 picks, and all time.
Performance ratio is the one that catches the bullshit. It's actual profit divided by expected profit — a calibration check. A model with positive ROI but a performance ratio of 0.6 is getting lucky, and luck eventually runs out. A model with negative ROI but a ratio near 1.0 is accurately predicting its own losses — the calibration is right, the edge estimate is off. You see both numbers side by side. You can tell the difference.
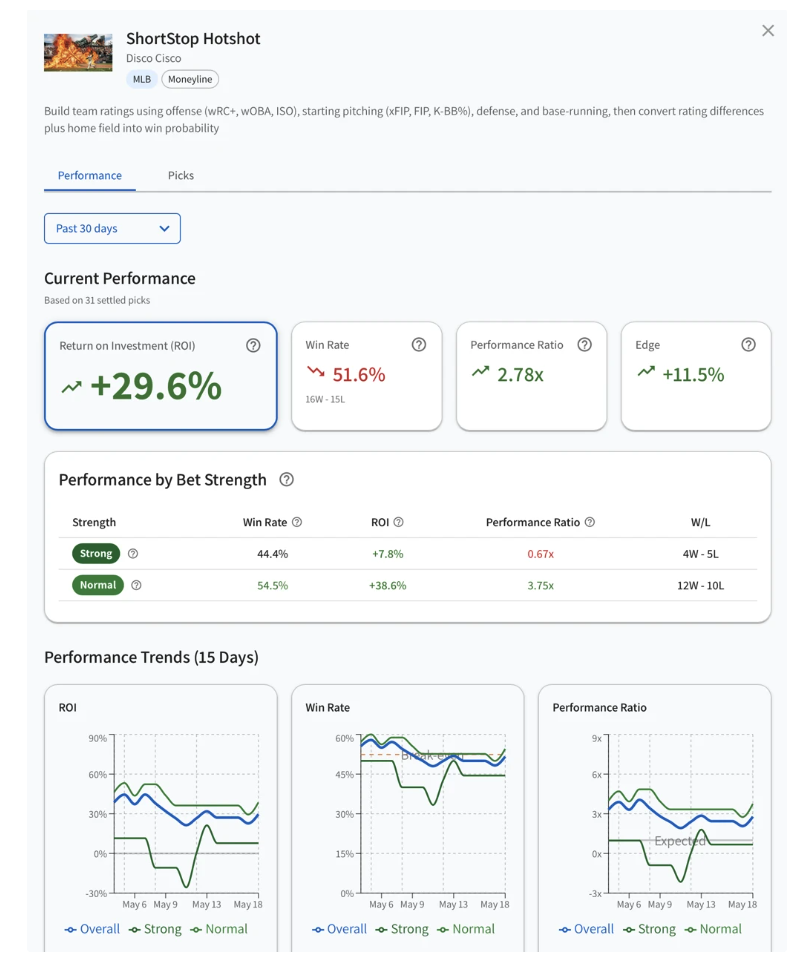
That's not a hot streak you can hide behind. You can check whether high-confidence picks actually outperform, whether recent form matches long-term, whether the strategy holds up over a meaningful sample, and whether the model's calibration is real or it's just running hot. Pull up any model on the platform and see for yourself before you decide whether to trust it.
The components aren't the hard part. The algorithms exist in open-source libraries. The Bayesian optimization math has been in textbooks for decades. The validation techniques are peer-reviewed. The hard part has always been running all of them, correctly, in sequence, on every model, before you bet real money.
Moddy does that. You bring the sports thesis. Moddy builds it thousands of ways, tests hundreds of strategies on top of it, proves the edge is real, and publishes the live performance for anyone to check.
No PhD required. Start building your first model.










